
I am pleased to announce the Clinical Trial Risk Tool, which is now open to the public to use.
The tool is available at https://clinicaltrialrisk.org/tool.
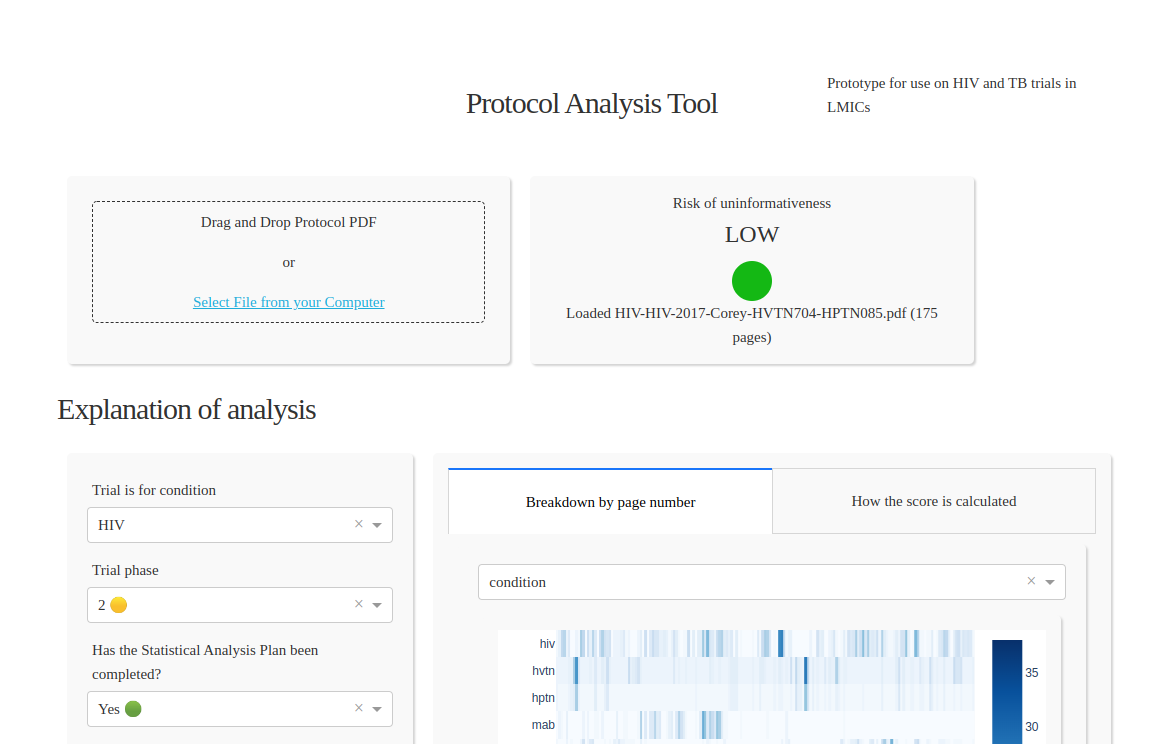
Screenshot of the tool
The tool consists of a web interface where a user can upload a protocol in PDF or Word format, and ultimately a number of features were extracted, such as number of subjects, statistical analysis plan, effect size, number of countries, etc.
The tool which can estimate the risk of HIV and TB trials ending uninformatively and will soon be extended to cover other metrics such as trial complexity and cost.
The NLP model was developed as an ensemble of components which extracted different aspects of information from the text, including rule-based (hand-coded) and neural network designs.
The model’s output features were then condensed down via a clinical trials risk model which ultimately produces a three-level risk traffic light score. The full analysis can be exported as XLSX or PDF.

Estimating the total cost of a clinical trial before it runs is challenging. Public data on past trial costs can be hard to come by, as many companies guard this information carefully. Trials in high income countries and low and middle income countries have very different costs. Upload your clinical trial protocol and create a cost benchmark with AI Protocol to cost benchmark The Clinical Trial Risk Tool uses AI and Natural Language Processing (NLP) to estimate the cost of a trial using the information contained in the clinical trial protocol.
You can download a white paper about clinical trial cost benchmarking here Estimating the total cost of a clinical trial before it runs is challenging. Public data on past trial costs can be hard to come by, as many companies guard this information carefully. Trials in high income countries and low and middle income countries have very different costs. Clinical trial costs are not normally distributed.[1] I took a dataset of just over 10,000 US-funded trials.

Guest post by Safeer Khan, Lecturer at Department of Pharmaceutical Sciences, Government College University, Lahore, Pakistan Introduction The success of clinical studies relies heavily on proper financial planning and budgeting. These processes directly impact key factors such as project timelines, resource allocation, and compliance with regulatory requirements. The accurate forecasting of costs for clinical trials, however, is a highly complex and resource-intensive process. A study by the Tufts Center for the Study of Drug Development found that the average cost of developing a new drug is approximately $2.